고정 헤더 영역
상세 컨텐츠
본문
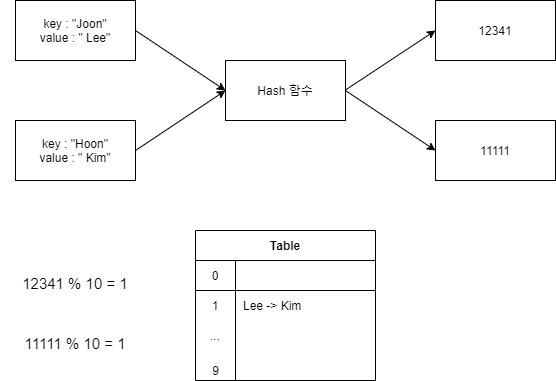
Hash
- key - value, Hash 함수, Hash 테이블 3가지로 설명할 수 있다.
- 특정 key 값을 hash 함수에 대입하면 값을 반환하도록 설계된다.
- 반환된 값에 바탕으로 테이블의 크기 값으로 나눠 hash 테이블에 저장하게 된다.
- 위와 값이 table의 key값이 같은 경우 보통적으로 linked list로써 chaining hash를 구성한다. 하지만 linked list가 무한히 길어질 수 는 없기 때문에 이에 대해 LRU 방식 혹은 특정 길이 이상 길어질 경우 linked list를 리셋하는 방식을 사용한다.
- 생각해보기 : 위의 hash 방식을 사용하여 load balancer를 디자인 하는것은 좋은 방법일까?
- 단일 서버 환경에서는 좋은 방법일 수 있다.
- 하지만 naver, kakao, google등과 같은 몇만대의 서버를 구성하고 sacle out과 장애 대응의 문제를 해결해야한다면 NO!
- 서버가 추가되고 장애 서버를 제거하는 상황이 발생한다면 hash table을 지속적으로 갱신하여야하고 hit rate가 현저하게 감소하는 현상이 발생한다. 이는 cache memory를 사용하는 의미가 없어지게 만들 수 있다.
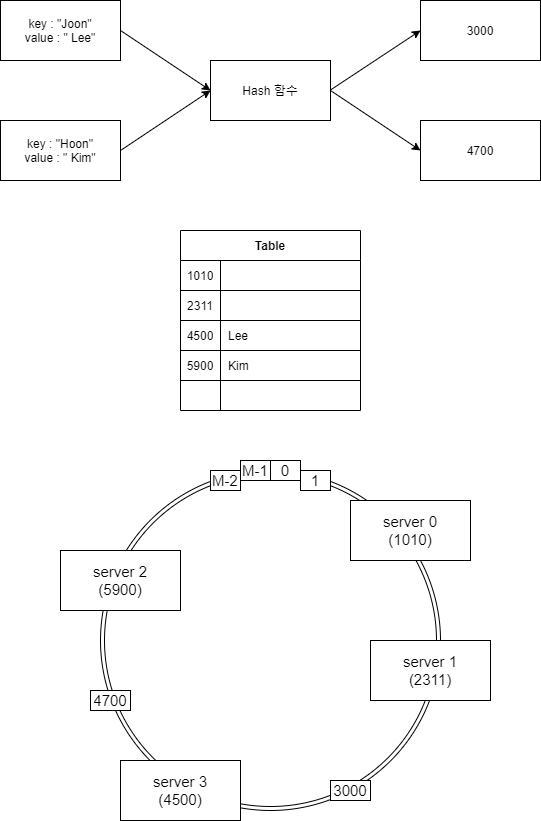
Consistent hasing
- 기본적인 hash와 구성요소는 똑같다. 하지만 작동 방식에서 조금 다르다.
- 작동방식
- 특정 key 값에 대하여 hash 함수로 부터 값을 반환하도록 설계된다.
- 반환된 값에 대한 정확한 key값이 hit 되는 형식이 아닌 나의 key값 보다 큰 hash table의 key 값에 대응되도록 table을 만든다.
- ex) 위의 테이블에서 Joon → 3000 → 4500으로 대응이 되는 형식. 만약 5900보다 더 큰값이라면 1010으로 대응된다.
- 만약 특정 서버가 장애가 생긴다면?. hash table 상의 특정 server의 값을 다음 hash table의 key 값에 대응되는 서버로 넘겨주도록 설정한다.
- 특정 서버가 추가 된다면?. 특정 서버의 key 값에 해당하는 부분을 찾아 bucket을 다 이동시킨다.
- consistent hasing은 만능인가??. 세상에 어느 방법도 만능이지는 않다.
- ex) netflix에서 인간수업, 스위트홈의 인기로 인해 트래픽이 급증하게되고 hashing된 특정 서버로 부하가 몰리게 된다면 netflix의 CDN은 장애가 발생할것이다.
- 이를 해결하기 위해서 선택 할 수 있는 방법은 무엇일까??
- HAproxy에서 사용하는 제한 부하 알고리즘 + consistent hasing이 도움의 방법이 될 수 있다.
- 특정 서버에 부하가 몰리게 되면 부하가 일정치 이하인 서버로 트래픽을 옮겨 사용하는 방식이다.
- https://medium.com/vimeo-engineering-blog/improving-load-balancing-with-a-new-consistent-hashing-algorithm-9f1bd75709ed 참조.
'Computer Science > Network' 카테고리의 다른 글
| REST API (0) | 2024.03.28 |
|---|---|
| Naver에 접속 해보자 (0) | 2021.01.08 |
| TCP/IP illustrate 2 (0) | 2020.07.23 |
| TCP/IP illustrate 1 (0) | 2020.07.20 |
| DHCP (0) | 2020.07.09 |




